嫁ちゃん
文字列内の全角半角の区別をつけたいなー
わたし
文字列から1文字づつ取り出して、判定してみよう!
目次
はじめに
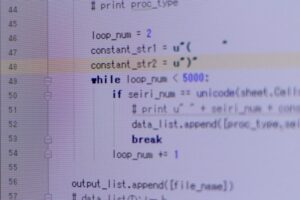
文字列から1文字づつ取り出して unicodedata.east_asian_width() を使って全角と半角を判定してみます。
用法
import unicodedata
ret = unicodedata.east_asian_width(chr)ユニコード文字 chr に割り当てられた east asian width を文字列で返します。
返り値(ret)
- East Asian Full-width (F)
- East Asian Half-width (H)
- East Asian Wide (W)
- East Asian Narrow (Na)
- East Asian Ambiguous (A)
- Not East Asian (Neutral)
例
import nicodedata
s = 'abcあいうえおdef'
for c in s:
print(c, unicodedata.east_asian_width(c))1文字毎に判定した結果が表示されていますね。
a Na
b Na
c Na
あ W
い W
う W
え W
お W
d Na
e Na
f Naおわりに
嫁ちゃん
文字と言っても、種類が色々とあるんですね。
わたし
そうだね。
文字の個数を数えるのか、バイト数を数えるのかハッキリしておかないと混乱するよ。
文字の個数を数えるのか、バイト数を数えるのかハッキリしておかないと混乱するよ。
[A8_TechAcademy065]
[Footer]